

最新新闻

热点文章
我要投稿

联系电话:027-87592219/20/21转188
投稿邮箱:tb@e-works.net.cn
投稿邮箱:tb@e-works.net.cn
文章推荐
视频推荐

- 未来汽车工厂,在线下单支持私人定制
- 2018-02-02

- 基于云端的三维CAD系统Autodesk Fusion 360
- 2018-01-31

- 通过PTC物联网技术实现Flowserve泵的预测性维护
- 2018-01-31

- 微软预测性维护保障电梯高效服务
- 2018-01-30

网联汽车预测性维护背后的数据科学
谈到Pivotal 使用数据科学为福特、宝马、奔驰和大众等汽车公司开发网联汽车应用,我们不得不先回顾下公司在数据科学领域的发展。早在网联汽车行业宣称将在 2020 年达到 45% 的复合年增长率之前,Pivotal 就已是该领域首批开始开发先进的数据科学驱动型应用的公司之一,亦是首批拿出汽车参考架构,用以开发实时的数据科学驱动型应用的公司之一。
Pivotal 的系列技术为此提供了非常合适的工具。例如,我们的这篇网联汽车博文讨论了如何借助流式处理或批处理通过 Spring Cloud Data Flow 之类的系统和 RabbitMQ 之类的消息传递系统(这两者都是我们参与的开源技术)实现数据摄取。这些系统可轻松地将数据从汽车摄入到 Apache Hadoop™ 后端(传感器数据的中立存储区)。传感数据进入 Hadoop 后,可以使用 Pivotal HDB(Pivotal 的 Hadoop 分发版产品)和由 Apache HAWQ (incubating) 提供支持的 Hadoop 原生 SQL 引擎将传其加载到 SQL 表中。

图 2:包括 DTC 和车辆参数的表的示例数据模型
图 2 是一个示例数据集的表,包括了DTC 以及出现 DTC 时记录的车辆参数。关系模型亦可采用,例如将VIN 作为维修、车辆或零件表的外键。此外,结构化数据源(如车辆数据和保修部分)还可以借助 Apache Sqoop 之类的技术从现有关系型数据库传入到 Hadoop 中,然后借助 Pivotal HDB 通过 SQL对其进行查询。
预测性维护的数据处理和特征创建
摄取车辆传感器数据和保修性维修数据后,我们就可以大规模地进行数据处理、特征创建和机器学习。我们借助 HAWQ 的大规模并行处理 (MPP) 架构来执行这些操作。例如,用于过滤纷杂传感器数据的信号处理操作可以在具有 PB 级数据集的高性能环境中运行。更复杂的贝叶斯过滤(例如卡尔曼滤波)可以在 HAWQ 和 HDFS 节点上并行执行。这些 Jupyter 笔记本演示了一些信号处理操作的示例。同样地,特征创建也可以在 HAWQ 上大规模执行。
对于处理过的预测性维护问题,我们将 DTC 与其他变量(例如先前的作业/维修类型、相同作业之间相隔的天数、里程计读数等)向量化了。这些变量成为了一个单一的、高维的(虽然稀疏)特征向量。特征向量是在给定车辆两次连续同类维修之间的时间窗口上创建的。我们对窗口结束日期做了实验:先将其分别设置为 1 天、15 天、30 天和 60 天,之后观察相应窗口期间的后续维修和聚合的 DTC 及其他变量信息。这个实验隐含目的是评估能否提前捕获后续维修。我们的分析显示:虽然模型的预测能力在维修日期之前的 1-2 个月有些损失,但损失并不明显,这意味着关键 DTC 出现得较早。
预测性维护的机器学习
要开始机器学习设计过程,我们面临着多类别/多标签问题。据作业/维修精度而定,,其中类别的数量可能非常大(可能是以 1000 作为数量级)。如上所述,这种类型的精度意味着每个类别标签只有很少的训练示例。如此一来,学习有意义的类别条件分布就变得很有挑战性。这个问题类似于一个大型文献集的多个标注。为了解决这一问题,我们采用了分层方法。我们首先构建了一个分类器来预测主系统相关的维修工作。其中一个类别就是一个诸如变速器、检修系统、引擎、悬挂系统之类的系统。为了预测每个主系统的维修工作,我们集合了给定系统下所有子系统的训练示例,并为它们分配了相同的类别标签。然后,我们针对每个系统的子系维修工作进行了预测。
对于多类别分类,我们借助Python Scikit-learn 函数(例如罗吉斯回归和随机森林)通过 HAWQ 上 PL/Python 用户定义的函数构建了一个并行的“一对多”多类分类器。
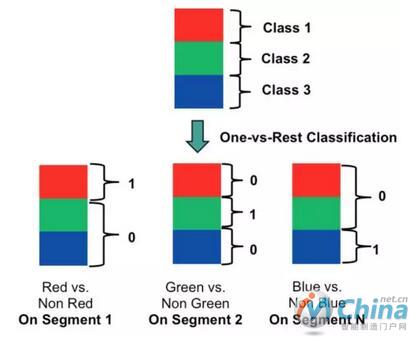
图 3:并行“一对多”多类分类器
图 3 展示了 HAWQ 上的“一对多”多类分类器的并行化,其中每个分类器(即分类器数量等于类别标签的数量)均在单独的数据节点或节点上构建并运行。对于感兴趣的读者,我们已将用于并行模型构建的“一对多”多类数据准备打包为 PDLTools 中的工具函数,PDLTools 是Pivotal Data Science 团队为 Pivotal MPP 平台开发的公开可用的数据科学函数库。基本模型也可以使用 Apache MADlib 进行构建。
实现预测性维护解决方案
模型构建完成后,要发挥价值的唯一方式就是要让汽车制造商、经销商和车队管理团队采用它,用于改善其客户体验。我们看到,有些客户将机器学习模型与托管在 Pivotal Cloud Foundry 上的 Web 应用集成。例如,一个应用可能会持续对汽车上的数据流进行评分,并通知与问题相关的司机、经销商和制造商。Pivotal Data Science 团队已经建立了使用 Flask 构建 Web 应用的样板,Flask 是一个基于 Python 的 Web 框架,可使用基于 Pivotal HDB 和 Pivotal Greenplum 建立的模型进行预测和洞察。有兴趣的读者可以在此处找到样板代码。
为了实现我们的模型,我们需要一个应用来评估一些信息并采取相应行动,例如在 DTC 事件触发时启动工作流程。对于这种实时事件评估,应用可以使用一些内存中数据集、流传输功能、事件通知或模型定义(如 PMML),以允许应用对传入数据的某一方面进行评估。Pivotal Gemfire(即 Apache Geode)是一个超低延迟的内存中数据网格,它可以作为通过 PMML 在 HAWQ 或 Greenplum 中构建的模型的缓存层。下面图 4 展示了使用 Pivotal 技术的实时/接近实时模型实现的示例架构。
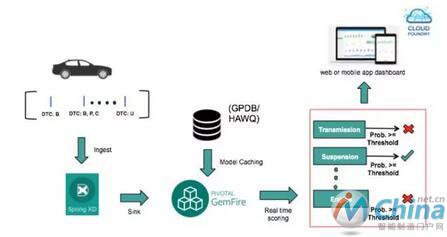
图 4 Pivotal 技术的实时模型实现的示例架构
在汽车工程生命周期的广阔蓝图中,这种网联汽车应用在真实世界的运用只是第一步。公司通常会将这样的初始计划视为概念验证,随后是早期市场测试计划。这一定会引发对能够解决数据粒度、采样频率、车内外处理、替代算法等问题的未来架构的讨论。
本文来源于互联网,e-works本着传播知识、有益学习和研究的目的进行的转载,为网友免费提供,并以尽力标明作者与出处,如有著作权人或出版方提出异议,本站将立即删除。如果您对文章转载有任何疑问请告之我们,以便我们及时纠正。联系方式:editor@e-works.net.cn tel:027-87592219/20/21。
- 上一篇文章:预测性维护:工业数字化转型的基石
- 下一篇文章:“预测性维修”服务,为工业智能制造升级