



投稿邮箱:tb@e-works.net.cn

- 未来汽车工厂,在线下单支持私人定制
- 2018-02-02

- 基于云端的三维CAD系统Autodesk Fusion 360
- 2018-01-31

- 通过PTC物联网技术实现Flowserve泵的预测性维护
- 2018-01-31

- 微软预测性维护保障电梯高效服务
- 2018-01-30

数据可视化:手把手打造BI
这里给出topSalary的计算,比较繁琐。
topSalery = IFERROR(mid(DataAnalyst[salary],SEARCH("-",DataAnalyst[salary],1)+1,LEN(DataAnalyst[salary])-SEARCH("-",DataAnalyst[salary],1)-1),DataAnalyst[bottomSalery])
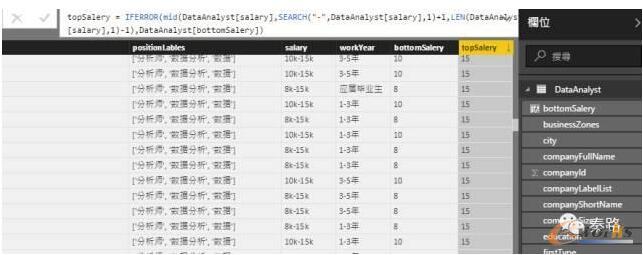
图9 topSalary的计算
之后新建一列使用(DataAnalyst[bottomSalery]+DataAnalyst[topSalery])/2 计算该岗位的平均工资。
大家看到这里,是不是觉得DAX公式非常长?新手可以多增加辅助列来进行计算。
Excel中有比较方便的分列功能,那么Power BI中是否拥有呢?答案是肯定的,右键点击列,选择编辑查询选项。

图10 编辑查询
这里依旧吐槽翻译。分割资料行就是我们熟悉的分列功能。选择自定义,用“-”即可完成分列(原始数据会被拆分,所以建议先复制一列)。
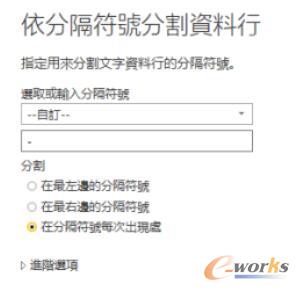
图11 分割资料
实战篇提到过,我们的北京数据是有重复值的,那么我们通过positionId这职位的唯一标示,来删除重复项。右键点击移除重复项目即可。
我们再看一下查询编辑的其他功能。
分组依据可以认为是数据透视表。可以选择多个字段进行分组。对结果进行求和、计数等操作。
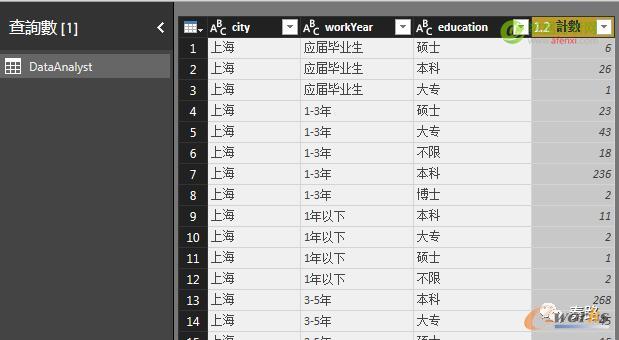
图12 数据透视表
如果是订单、用户行为、用户资料等大量数据,一般会以分组形式进行计算。不同分组字段,会生成不同的维度,像范例中的城市、工作年限,教育背景都是维度,也是图表的基础。如果生成的维度足够多,我们能利用维度组成数据模型,这是OLAP的概念。
除此以外,也能利用过滤直接筛选数据。我们选择出含有数据分析、分析的数据。排除掉大数据工程师等干扰职位。

图13 过滤直接筛选数据
这里支持多条件复杂逻辑筛选。
到这里,我们已经完成实战篇中的清洗过程中,我这次简单化了。以上步骤都能通过右侧的套用步骤还原和撤销。这里不会出现bottomSalery这类列。
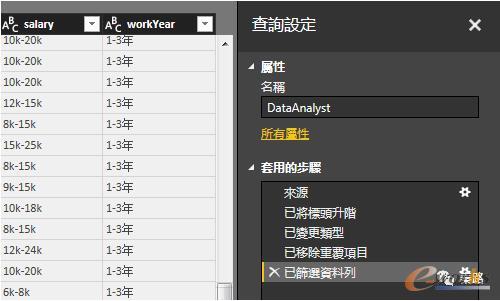
图14 套用步骤还原和撤销
之后选择工具栏的关闭并套用,报表数据就会更新。最后数据2300多行。
通过数据查询和报表DAX公式,我们就能完成数据清洗和规整的步骤。主要思路是:移除重复值、过滤目标数据、清洗脏数据、数据格式转换。
- 第1页:数据可视化:手把手打造BI(1)
- 第2页:数据可视化:手把手打造BI(2)
- 第3页:数据可视化:手把手打造BI(3)
- 第4页:数据可视化:手把手打造BI(4)
- 第5页:数据可视化:手把手打造BI(5)
- 上一篇文章:什么是商业智能BI和实施BI的解决方案
- 下一篇文章:傅一平:为什么BI取数这么难?