



投稿邮箱:tb@e-works.net.cn

- 未来汽车工厂,在线下单支持私人定制
- 2018-02-02

- 基于云端的三维CAD系统Autodesk Fusion 360
- 2018-01-31

- 通过PTC物联网技术实现Flowserve泵的预测性维护
- 2018-01-31

- 微软预测性维护保障电梯高效服务
- 2018-01-30

面向大规模定制的Web零件库的研究
3.4 基于本体的零件检索
使用本体的目的是提高检索的查全率,实现多种推理检索。WebParts中的零件检索并不是针对具体的零件实例,而是针对零件族的。
传统的查询以关键词匹配和布尔查询为主,无法实现同义概念(螺母、螺帽)、上下位概念(螺钉、内六角螺钉)的检索,因而在WebParts中,提出多层次的检索模型(如图8)。
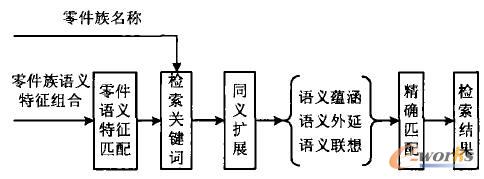
图8 多层次检索模型
(1)零件语义特征匹配 根据零件的功能结构特征关键词组合进行匹配查询,得到满足匹配条件的零件族本体关键词。
(2)语义检索 采用基于本体的语义检索方式,能检索出与用户查询中所表达的具有同义、上下位等语义关系的实例信息。语义检索包括4个方面:①同义扩展检索。如第1.4节所述,表达同一概念的零件族节点可能有多种名称表达方式,分别为本体和关联本体,同义扩展将有关本体的关联本体检索出来。②语义蕴涵检索。本体概念之间存在上下位关系,蕴涵是下位关系。例如,用户输入“螺栓”,要求把所有符合条件的六角头螺栓、内六角螺栓和沉头螺栓等全列出来。③语义外延检索。根据蕴涵检索,输入“六角头螺栓”,外延检索时需要把满足条件的螺栓列出。④语义联想检索。概念的并列关系检索,例如输入“螺栓”,检索“螺钉”,也就是将父节点本体的所有子类本体检索出来。
(3)精确检索 即精确匹配,通过前面的检索过程,可以得到一个本体列表,通过这个本体列表逐一构建对应的零件族的树,树的底端是零件相似族,它与零件实例相对应。
在语义检索中,WebParts的本体推理搜索引擎利用本体读写 API(jena ontology API)对以OWL文件格式保存的本体库和关联本体库进行查询操作。
4 Web零件库中的关键技术
4.1 基于HTTP隧道的对象串行化通讯
在WebParts的客户端,大量使用Java applet来完成零件树的生成、事物特性表的定义与编辑,以及零件事物特性一览表的显示等功能,服务器则使用Java Servlet,因此WebParts主要的通讯问题存在于applet与Servlet之间。基于几方面考虑,决定采用基于HTTP隧道的对象串行化通讯方式来实现applet与Servlet之间的数据交换。
(1)基于HTTP隧道的通讯过程
客户端的applet首先要创建一个到服务器Servlet的HTTP链接(URLConnection),基于此打开一个输出流DataOutputStream——即建立HTTP通讯隧道,然后将想要传递的参数以“?paramName=param Value¶mName2=paramValue2”的形式,通过当前打开的输出流传递到服务器Servlet上。Servlet解析出来自客户端的请求参数,执行相应的逻辑操作,将结果以序列化了的对象形式,通过基于HTTP隧道的输入流DataInputStream返回到客户端。通讯过程中,打开了的HTTP隧道将一直保持到通讯结束后才关闭。
(2)服务器通讯字典
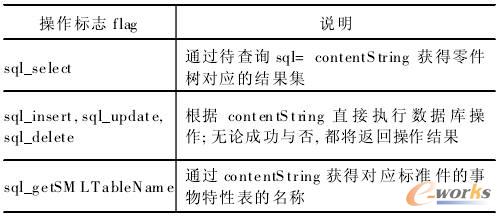
客户端传递参数是以”url?“的形式进行的,理论上可以传递多个参数/值对。在 WebParts中规定只传递两个参数/值对“第一个参数表达需要执行的操作类型,即作为操作标志;第二个参数为具体内容,也可为空。因此,服务器需要建立一个通讯字典,根据来自客户端的参数执行相应的逻辑操作,以flag和contentString分别标志第一参数和第二个参数的值。WebParts服务器中的通讯字典部分内容如表1所示。
表1 WebParts服务器通讯字典部分内容
4.2 数据缓存
为了提高系统的速度,降低服务器的响应压力,在Web服务器启动时,WebParts将大量常用数据加载到内存中,客户通过网络请求所需数据时,服务器不再检索数据库,而直接从内存中提取并返回给客户端。
例如,WebParts系统中零件树是从数据库提取数据动态生成的,这个过程比较耗时。服务器以Hashtable的形式保存各种零件树数据。用户浏览某个企业的零件树时,客户端通过HTTP通讯隧道向服务器发送企业ID,服务器Servlet直接从Hashtable中获取并返回。另一方面,通过查询零件关键词直接生成零件树,企业用结构化查询语言(Structured Query Language,SQL)为关键词保存查询结果,第二次查询时可以直接利用以往的查询结果,不需要再进行复杂的数据库查询操作。
- 上一篇文章:三维协同设计方法在飞机起落架设计中的应用
- 下一篇文章:舰载机机翼模型的快速建模技术