

最新新闻

热点文章
我要投稿

联系电话:027-87592219/20/21转188
投稿邮箱:tb@e-works.net.cn
投稿邮箱:tb@e-works.net.cn
文章推荐
视频推荐

- 未来汽车工厂,在线下单支持私人定制
- 2018-02-02

- 基于云端的三维CAD系统Autodesk Fusion 360
- 2018-01-31

- 通过PTC物联网技术实现Flowserve泵的预测性维护
- 2018-01-31

- 微软预测性维护保障电梯高效服务
- 2018-01-30

大数据分析你不能不懂的6个核心技术
目前,大数据领域每年都会涌现出大量新的技术,成为大数据获取、存储、处理分析或可视化的有效手段。大数据技术能够将大规模数据中隐藏的信息和知识挖掘出来,为人类社会经济活动提供依据,提高各个领域的运行效率,甚至整个社会经济的集约化程度。
4.大数据存储与管理
传统的数据存储和管理以结构化数据为主,因此关系数据库系统(RDBMS)可以一统天下满足各类应用需求。大数据往往是半结构化和非结构化数据为主,结构化数据为辅,而且各种大数据应用通常是对不同类型的数据内容检索、交叉比对、深度挖掘与综合分析。面对这类应用需求,传统数据库无论在技术上还是功能上都难以为继。因此,近几年出现了oldSQL、NoSQL 与NewSQL 并存的局面。总体上,按数据类型的不同,大数据的存储和管理采用不同的技术路线,大致可以分为3类。第1类主要面对的是大规模的结构化数据。针对这类大数据,通常采用新型数据库集群。它们通过列存储或行列混合存储以及粗粒度索引等技术,结合MPP(Massive Parallel Processing)架构高效的分布式计算模式,实现对PB 量级数据的存储和管理。这类集群具有高性能和高扩展性特点,在企业分析类应用领域已获得广泛应用;第2类主要面对的是半结构化和非结构化数据。应对这类应用场景,基于Hadoop开源体系的系统平台更为擅长。它们通过对Hadoop生态体系的技术扩展和封装,实现对半结构化和非结构化数据的存储和管理;第3类面对的是结构化和非结构化混合的大数据,因此采用MPP 并行数据库集群与Hadoop 集群的混合来实现对百PB 量级、EB量级数据的存储和管理。一方面,用MPP 来管理计算高质量的结构化数据,提供强大的SQL和OLTP型服务;另一方面,用Hadoop实现对半结构化和非结构化数据的处理,以支持诸如内容检索、深度挖掘与综合分析等新型应用。这类混合模式将是大数据存储和管理未来发展的趋势。
5.大数据计算模式与系统
计算模式的出现有力推动了大数据技术和应用的发展,使其成为目前大数据处理最为成功、最广为接受使用的主流大数据计算模式。然而,现实世界中的大数据处理问题复杂多样,难以有一种单一的计算模式能涵盖所有不同的大数据计算需求。研究和实际应用中发现,由于MapReduce主要适合于进行大数据线下批处理,在面向低延迟和具有复杂数据关系和复杂计算的大数据问题时有很大的不适应性。因此,近几年来学术界和业界在不断研究并推出多种不同的大数据计算模式。
所谓大数据计算模式,即根据大数据的不同数据特征和计算特征,从多样性的大数据计算问题和需求中提炼并建立的各种高层抽象(abstraction)或模型(model)。例如,MapReduce 是一个并行计算抽象,加州大学伯克利分校著名的Spark系统中的“分布内存抽象RDD”,CMU 著名的图计算系统GraphLab 中的“图并行抽象”(Graph Parallel Abstraction)等。传统的并行计算方法,主要从体系结构和编程语言的层面定义了一些较为底层的并行计算抽象和模型,但由于大数据处理问题具有很多高层的数据特征和计算特征,因此大数据处理需要更多地结合这些高层特征考虑更为高层的计算模式。
根据大数据处理多样性的需求和以上不同的特征维度,目前出现了多种典型和重要的大数据计算模式。与这些计算模式相适应,出现了很多对应的大数据计算系统和工具。由于单纯描述计算模式比较抽象和空洞,因此在描述不同计算模式时,将同时给出相应的典型计算系统和工具,如表1所示,这将有助于对计算模式的理解以及对技术发展现状的把握,并进一步有利于在实际大数据处理应用中对合适的计算技术和系统工具的选择使用。
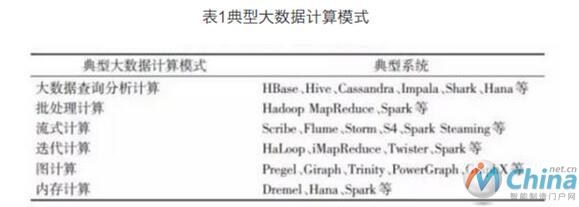
表1 典型大数据计算模式
6.大数据分析与可视化
在大数据时代,人们迫切希望在由普通机器组成的大规模集群上实现高性能的以机器学习算法为核心的数据分析,为实际业务提供服务和指导,进而实现数据的最终变现。与传统的在线联机分析处理OLAP不同,对大数据的深度分析主要基于大规模的机器学习技术,一般而言,机器学习模型的训练过程可以归结为最优化定义于大规模训练数据上的目标函数并且通过一个循环迭代的算法实现,如图4所示。因而与传统的OLAP相比较,基于机器学习的大数据分析具有自己独特的特点。

图4 基于机器学习的大数据分析算法目标函数和迭代优化过程
(1)迭代性:由于用于优化问题通常没有闭式解,因而对模型参数确定并非一次能够完成,需要循环迭代多次逐步逼近最优值点。
(2)容错性:机器学习的算法设计和模型评价容忍非最优值点的存在,同时多次迭代的特性也允许在循环的过程中产生一些错误,模型的最终收敛不受影响。
(3)参数收敛的非均匀性:模型中一些参数经过少数几轮迭代后便不再改变,而有些参数则需要很长时间才能达到收敛。
这些特点决定了理想的大数据分析系统的设计和其他计算系统的设计有很大不同,直接应用传统的分布式计算系统应用于大数据分析,很大比例的资源都浪费在通信、等待、协调等非有效的计算上。
传统的分布式计算框架MPI(message passing interface,信息传递接口)虽然编程接口灵活功能强大,但由于编程接口复杂且对容错性支持不高,无法支撑在大规模数据上的复杂操作,研究人员转而开发了一系列接口简单容错性强的分布式计算框架服务于大数据分析算法,以MapReduce、Spark和参数服务器ParameterServer等为代表。
分布式计算框架MapReduce将对数据的处理归结为Map和Reduce两大类操作,从而简化了编程接口并且提高了系统的容错性。但是MapReduce受制于过于简化的数据操作抽象,而且不支持循环迭代,因而对复杂的机器学习算法支持较差,基于MapReduce的分布式机器学习库Mahout需要将迭代运算分解为多个连续的Map 和Reduce 操作,通过读写HDFS文件方式将上一轮次循环的运算结果传入下一轮完成数据交换。在此过程中,大量的训练时间被用于磁盘的读写操作,训练效率非常低效。为了解决MapReduce上述问题,Spark 基于RDD 定义了包括Map 和Reduce在内的更加丰富的数据操作接口。不同于MapReduce 的是Job 中间输出和结果可以保存在内存中,从而不再需要读写HDFS,这些特性使得Spark能更好地适用于数据挖掘与机器学习等需要迭代的大数据分析算法。基于Spark实现的机器学习算法库MLLIB已经显示出了其相对于Mahout 的优势,在实际应用系统中得到了广泛的使用。
近年来,随着待分析数据规模的迅速扩张,分析模型参数也快速增长,对已有的大数据分析模式提出了挑战。例如在大规模话题模型LDA 中,人们期望训练得到百万个以上的话题,因而在训练过程中可能需要对上百亿甚至千亿的模型参数进行更新,其规模远远超出了单个节点的处理能力。为了解决上述问题,研究人员提出了参数服务器(Parameter Server)的概念,如图5所示。在参数服务器系统中,大规模的模型参数被集中存储在一个分布式的服务器集群中,大规模的训练数据则分布在不同的工作节点(worker)上,这样每个工作节点只需要保存它计算时所依赖的少部分参数即可,从而有效解决了超大规模大数据分析模型的训练问题。目前参数服务器的实现主要有卡内基梅隆大学的Petuum、PSLit等。
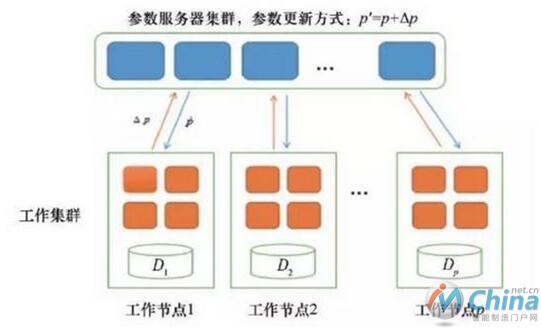
图5 参数服务器工作原理
在大数据分析的应用过程中,可视化通过交互式视觉表现的方式来帮助人们探索和理解复杂的数据。可视化与可视分析能够迅速和有效地简化与提炼数据流,帮助用户交互筛选大量的数据,有助于使用者更快更好地从复杂数据中得到新的发现,成为用户了解复杂数据、开展深入分析不可或缺的手段。大规模数据的可视化主要是基于并行算法设计的技术,合理利用有限的计算资源,高效地处理和分析特定数据集的特性。通常情况下,大规模数据可视化的技术会结合多分辨率表示等方法,以获得足够的互动性能。在科学大规模数据的并行可视化工作中,主要涉及数据流线化、任务并行化、管道并行化和数据并行化4 种基本技术。微软公司在其云计算平台Azure 上开发了大规模机器学习可视化平台(Azure Machine Learning),将大数据分析任务形式为有向无环图并以数据流图的方式向用户展示,取得了比较好的效果。在国内,阿里巴巴旗下的大数据分析平台御膳房也采用了类似的方式,为业务人员提供的互动式大数据分析平台。
本文来源于互联网,e-works本着传播知识、有益学习和研究的目的进行的转载,为网友免费提供,并以尽力标明作者与出处,如有著作权人或出版方提出异议,本站将立即删除。如果您对文章转载有任何疑问请告之我们,以便我们及时纠正。联系方式:editor@e-works.net.cn tel:027-87592219/20/21。