



投稿邮箱:tb@e-works.net.cn

- 未来汽车工厂,在线下单支持私人定制
- 2018-02-02

- 基于云端的三维CAD系统Autodesk Fusion 360
- 2018-01-31

- 通过PTC物联网技术实现Flowserve泵的预测性维护
- 2018-01-31

- 微软预测性维护保障电梯高效服务
- 2018-01-30

基于数控流水线技术的开放式数控系统(下)
3.2 实验结果
实验通过运行一个三轴联动的铣削程序进行测试,加工轨迹如图 10 所示。
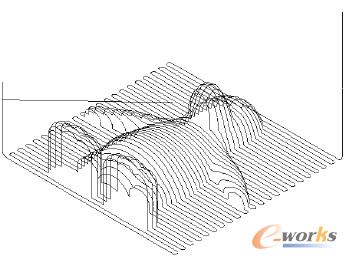
图10 实验中加工程序的刀具轨迹
加工程序中包含大量微线段,有利于测试系统在大运算量下的表现。实验中NCM 缓冲区总大小为ST =2 000 字节,临界值SC=1 000 字节。NCMP 的进给轴指令脉冲的最大速率为125 K/s,机床脉冲当量设置为0.1 μm,此时NCM 代码的执行速率R≈2.44K 字节/s。根据式(1)~式(3)可得TLC=0.410 s,TIAM=0.410s,TFB=0.820 s。实验中运行的加工程序总时间约为17.8 min。本次实验通过使用分析工具对数控主控流水线线程进行了分析。表 5 列举了流水线中相关模块的一些特性。按照表5 中的数据绘制成的强实时功能与各指标间的关系如图11 所示。
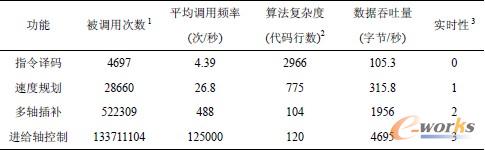
注:
1. 指令译码、速度规划和多轴插补的调用次数是程序运行时相关函数的调用次数;进给轴控制的算法的调用次数是程序运行时输入到进给
轴控制NCM 执行器件的时钟次数(每个时钟执行一次DDA 算法)。
2. 指令译码、速度规划和多轴插补的源代码是ANSI C 语言,进给轴控制的源代码是Verilog HDL 硬件描述语言。
3. 实时性以各模块在实时系统中的优先级顺序表示,数值越大实时性越强。
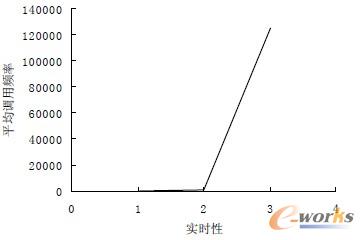
a 平均调用频率
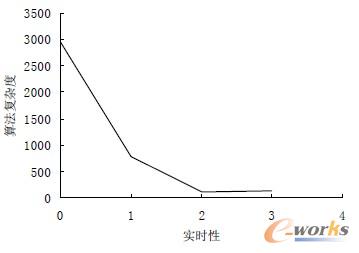
b 算法复杂度
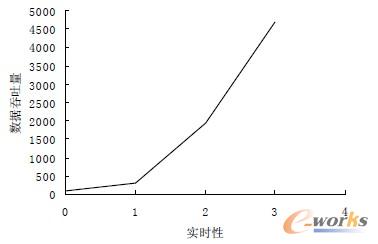
c 数据吞吐量
图 11 实验系统强实时功能指标变化趋势
可见,相关实验结果与本文图1 中的曲线的趋势基本一致。图12 是数控主控流水线线程的资源占用情况。
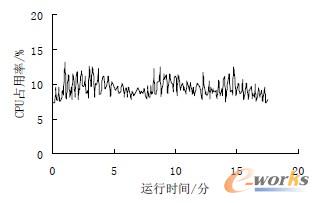
a CPU 占用率
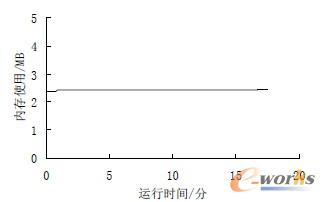
b 内存占用
图12 数控主控流水线线程的资源占用情况
从图中可以看出,在实验平台上,流水线线程的CPU 占用率小于15%,平均为10%左右。图12 数控主控流水线线程的资源占用情况内存使用量比较稳定,约为2.4 MB。可以看出,由于流水线线程的效率很高,使得系统可以有充裕的资源同时执行图形仿真、状态监视、网络通信等其他和数控系统相关的功能。需要指出的是,为了说明流水线线程的低资源占用,实验平台选择了基于ARM 的低成本单片机。如果选用更高级的嵌入式微控制器或采用基于PC 机的设计,将获得更高性能。
实时性方面,由于 NCMP 上的NCM 执行器件是靠硬件时钟驱动执行相关逻辑,因此不存在执行时间上的抖动,属于纯实时执行。然而,如果流水线其他任何部分不能满足实时性要求,会造成NCM 执行器件无法获得下一周期执行数据,此时将产生一个错误。在后续的实验中,系统长时间连续运行多个大型加工程序,运行过程中没有产生过上述错误,证明本文的数控流水线体系可以满足
4 结论
与通常的开放式系统方案相比,数控流水线技术不依赖于特定的软件或硬件环境,可以适应各种广泛的结构体系。数控流水线的主控流水线线程部分无需实时操作系统的支持,采用通用的编程手段构建,且充分发挥了通用操作系统运算效率高的优势。开放的标准化接口使不同版本流水线的模块的互换成为可能。NCMP 部分而采用了低成本、精简化的结构设计,NCM 代码的执行由硬件逻辑实现,具有极高的实时性和可靠性,且NCM 代码控制逻辑是可重构的,具有开放性。通过实验结果可以看出,本文提出的基于流水线技术的开放式数控系统方案是可行的而且流水线占用资源很少,为系统功能的进一步扩展留下了余地。
- 上一篇文章:CNC加工中心的工艺特点
- 下一篇文章:三伺服机械手在注塑机的研究与应用